
Note: AI is moving fast, so I expect this blog post to be out of date shortly after it is published
Introduction
AI is moving fast, but the foundational patterns are beginning to harden.
It is easy to get lost in the noise and the hype. So this is my brief guide on creating the start of an effective AI strategy for a DevOps team in 2026.
Roadmap
Step 1) Generative AI
This is how most people use LLMs today. If you are using ChatGPT or Gemini in a browser then you are already using Generative AI.
It is reactive. You ask a question, it gives an answer. That’s it.
This is the easiest and most valuable step to start embracing AI in your business.
Step 2) Prompt Engineering
Once you have mastered using an LLM like a search engine, you need to get better at Prompt Engineering.
Before:
"Convert this text into json plz."
After:
**System Prompt:**
You are a high-precision data extraction engine. Your goal is to parse unstructured text into a valid JSON object according to a strict schema.
**Instructions:**
Extract the requested fields only.
If a field is missing from the text, return null.
Ensure the output is only valid JSON. Do not include conversational filler like "Here is your data."
**Use the following schema:**
<schema>
{
"client_name": "string",
"project_type": "string (Web, Mobile, or Cloud)",
"estimated_budget": "number",
"technologies": ["string"],
"urgency_level": "string (Low, Medium, High)"
}
</schema>
**User Prompt:**
<context>
[Paste your messy text, email thread, or transcript here]
</context>
<example>
Input: "Hey, we need a new React web app. We have about 50k for it and need it done by next month. Reach out to Sarah at Acme Corp."
Output: {
"client_name": "Acme Corp",
"project_type": "Web",
"estimated_budget": 50000,
"technologies": ["React"],
"urgency_level": "High"
}
</example>
Please extract the data from the provided <context> now. Output JSON only.
This is a big topic that is worth learning. Here are resources to get started:
- https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/overview
- https://docs.aws.amazon.com/bedrock/latest/userguide/design-a-prompt.html
Step 3) Agentic AI
Agentic AI is the next level up.
If Generative AI is the chatbot, then Agentic AI is your digital employee.
You give Agentic AI a goal. It will decide which tools to use, how to sequence the steps, and how to verify if it succeeded.
It has boundless energy, and will enthusiastically tackle any problem you give it.
The challenges you face here though are:
- How to make it follow your tooling choices
- How to make it follow your design patterns
- How to review the code it generates
- How to secure the code it generates
- How to balance token spend against development speed
- … and lots more!
Without guardrails, it will gravitate towards its own bias and can easily create an expensive tangled mess.
However, with the right guidance, this is where Senior Engineers can start to multiply their productivity.
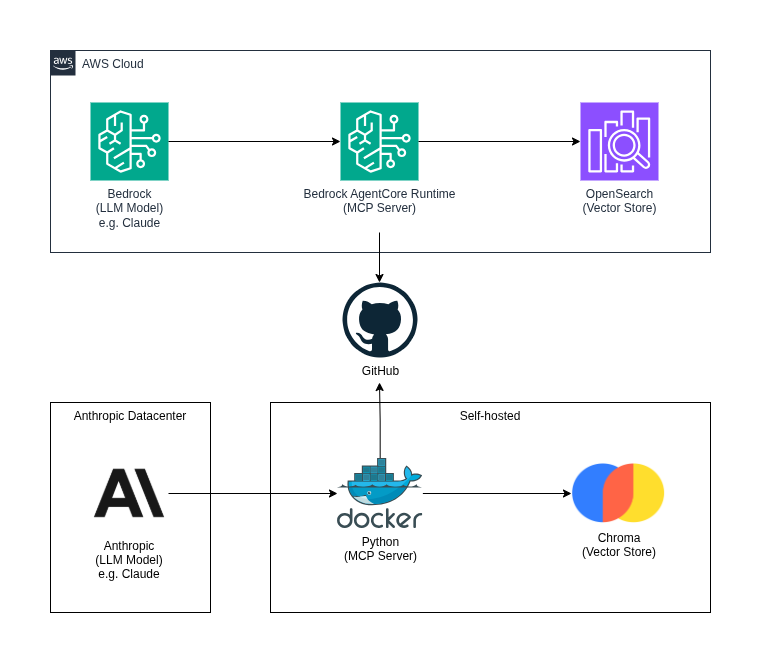
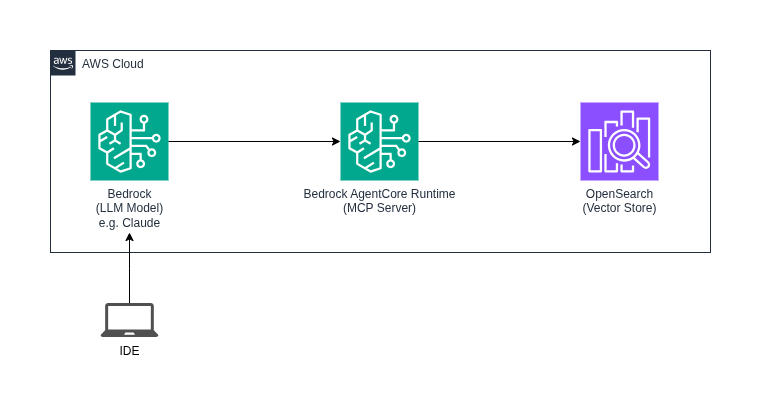
Step 4) MCP Server
You now have your Agentic AI, it can do lots of tasks in your terminal by using public resources.
But how can you let it connect to your documentation, your repos, and other tooling?
The Model Context Protocol (MCP) defines a standard way for AI applications to talk to external systems. MCP servers give models secure, structured access to specific capabilities. For example:
- Resources: Documentation, databases, etc.
- Tools: Jira, GitHub, etc.
- Prompts: Reusable prompt templates
The challenges here are how to do all of this securely, without accidentally giving your model access to wipe the production database.
Step 5) RAG
A RAG (Retrieval Augmented Generation) lets you index your own private data in a way that the LLM can use. We can use a vector store to hold our sensitive company information.
This allows us to ask the LLM questions that are specific to the company:
What did we decide in today's meeting?
What is our top selling product?
What is our security policy on BYOD?
The RAG will:
- Retrieval: Search the connected data to find relevant information. Leverage vector search to find meaning rather than just keywords.
- Augmentation: Inject this data into the prompt behind the scenes so that the AI understands the context.
- Generation: The LLM reads the provided context and writes a clear, concise answer.
Utilising RAGs can help reduce hallucination rates, because the model now has access to real data sources.
This step is where our models stop giving generic answers and start giving answers specific to our company.
Step 6) Data Sovereignty
You don’t have to send data to the model vendor’s cloud. You can run models like Claude, Llama, or others on your own infrastructure. For example via AWS Bedrock so that inference and data stay inside your environment and under your control.
This is particularly important in highly regulated enterprise environments where speed of development needs to be balanced against security.
Summary
I hope these 6 steps can help guide a roadmap for your DevOps team to utilise AI effectively.
Like a lot of work in DevOps, the key is understanding enough to make the judgement call on:
Speedvs.Securityvs.Cost
AI is young and fast moving, but the foundational patterns are beggining to harden. Now is the perfect time to adjust your roadmap to maximise the value AI can bring to your company.