

Introduction
Recently I had the need to implement a disaster recovery strategy for an Amazon Redshift cluster.
Having used RDS extensively in the past I was surprised to find out that Redshift doesn't offer the same features when it comes to implementing a disaster recovery strategy.
During this short article we will explore high level approaches for dealing with outages impacting single nodes, availability zones and regions.
We will also look at what options we have to simulate failure to test our disaster recovery process.
How Redshift Works
To give you a quick overview, Redshift is a cloud data warehouse based on PostgreSQL.
It was designed with machine learning and business intelligence tools in mind. This means it can scale to handle large volumes of data easily (petabyte scale!).
Redshift clusters are deployed into a single availability zone. Unlike RDS, these clusters contain a single leader node and multiple compute nodes.
Snapshots, snapshots, snapshots!
Unlike RDS, Redshift unfortunately does not support features like point in time recovery and standby instances in second availability zones.
The entire backup process relies on taking snapshots. These can be triggered manually or automatically.
Automatic backups can be scheduled using a Unix-like cron expression. So for example, you could take a backup every 8 hours with a 7 day retention.
Single Node Failure
Because Redshift is a fully managed service, it uses automated diagnostic checks to monitor and detect failed nodes that may prevent the cluster from perform normally.
When a failed node is detected, a node replacement is automatically triggered and the failed node is replaced during the maintenance window or immediately if AWS considers it a major failure.
It's not currently possible to shut down a Redshift cluster's node or simulate a node loss.
Availability Zone Failure
There are two options for recovering from an AZ failure:
- Restore a Snapshot
- Cluster Relocation
Restoring a snapshot is as easy as it sounds so we will focus on cluster relocation.
While Redshift takes in multiple availability zones, it doesn't actually run the cluster across multiple AZs. Rather, when it detects a failure it will relocate the cluster to the next availability zone. This process can take a few minutes.
Relocation Requirements
It's important to note that cluster relocation is only supported for the RA3 instance types. So if you're running a dc2.large instance type then you will need to restore snapshots manually.
Testing AZ Failover
Unfortuntely the AWS Fault Injection Simulator not support injecting faults into Redshift.
However, we can test what happens in an AZ failure by triggering a cluster relocation. You can either do this in the admin panel or via the CLI.
To use this feature, you need to ensure that the subnet group attached to the cluster contains subnets from more than one different AZ.
aws redshift modify-cluster \
--cluster-identifier mycluster \
--availability-zone eu-west-1aRegion Failure
At the time of writing this article Redshift only supports single region deployments.
However, you can enable cross-Region snapshots. This will automatically replicate the snapshots into another region, so if Ireland goes does then you could restore the snapshot sitting in London for example.
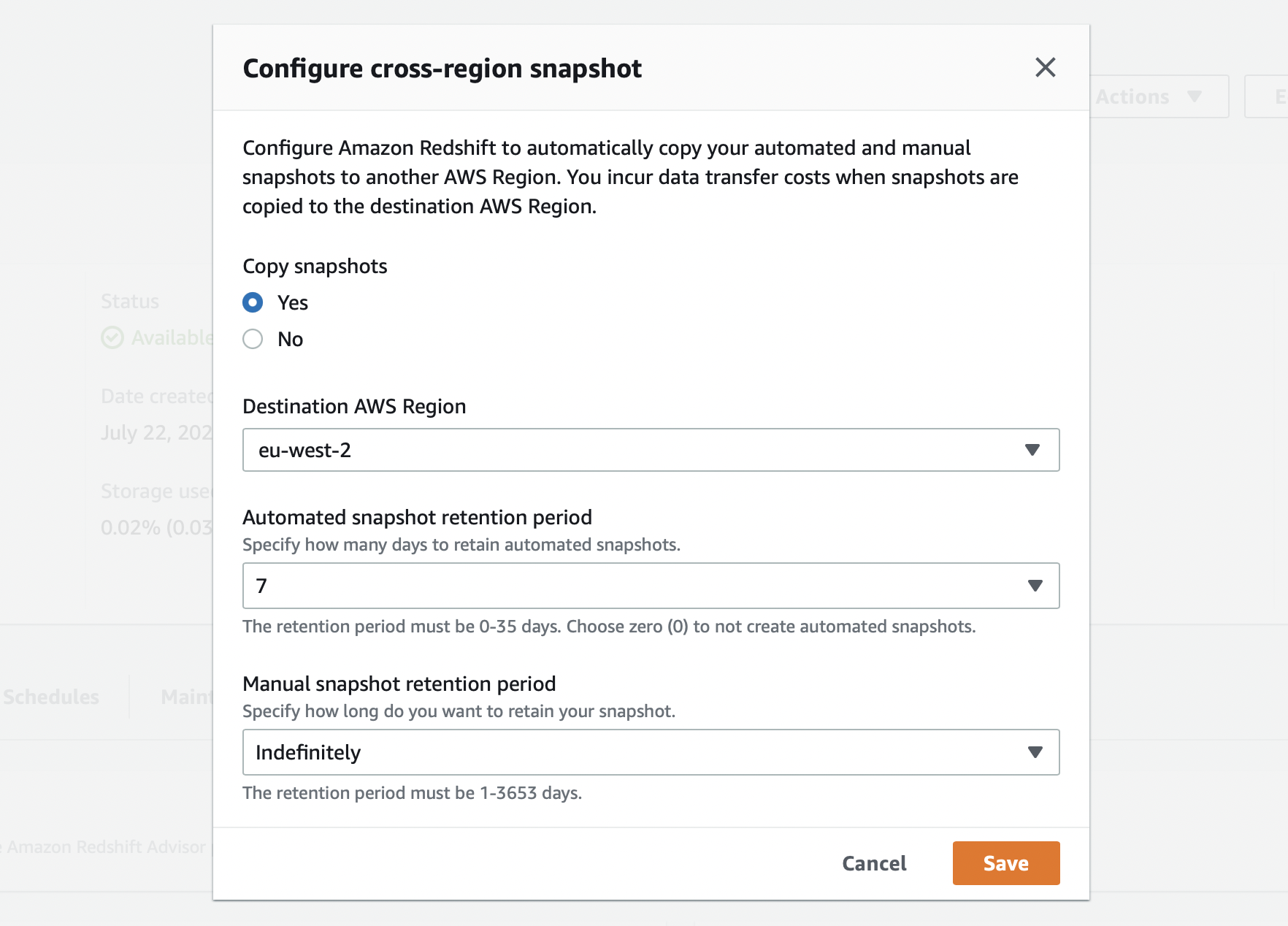
There is currently no way to automatically fail over to the second region, so you will need to manually restore the snapshot in the new region to recover the cluster.
Summary
Hopefully this has given you a high level overview of how to deal with different failure scenarios.
As you can see, Redshift disaster recovery is not as feature complete as RDS. Having less frequent backups unfortunately means higher RPOs.
However, this simplicity makes Redshift disaster recovery incredibly easy to document and test. Less options - less complexity!